AWS High Availability Architecture: Learn How to Create it!
AWS high-availability architecture removes single points of failure: run workloads in at least two Availability Zones, place instances behind an Application/Network Load Balancer, use Auto Scaling groups with ELB/EC2 health checks to replace bad instances, choose Multi-AZ data stores (e.g., RDS/Aurora), and add Amazon Route 53 health-check failover or multi-Region routing.
Businesses must now run their apps 24/7 in order to meet customer expectations. Failure in their apps results in unavailability, which frustrates customers. This leads to a loss of customer satisfaction, which eventually leads to a loss of business revenue.
In this article, we will introduce some basics about high availability infrastructures. How is high availability calculated and what it means. And for those interested in AWS Cloud, we look at AWS's high availability architecture, and its advantages, as well as an analysis of AWS computing, database, and storage services and what kind of availability they can bring.
High Availability definition
Failures in IT applications create downtime, which is a period of time when your system is not available for use or is unresponsive. For some companies each minute of downtime costs thousands of dollars.
High availability is a system’s ability to function even when some components fail. It guarantees continuous operability of systems for desirably long periods of time. High availability protects businesses against the risks brought by a system outage.
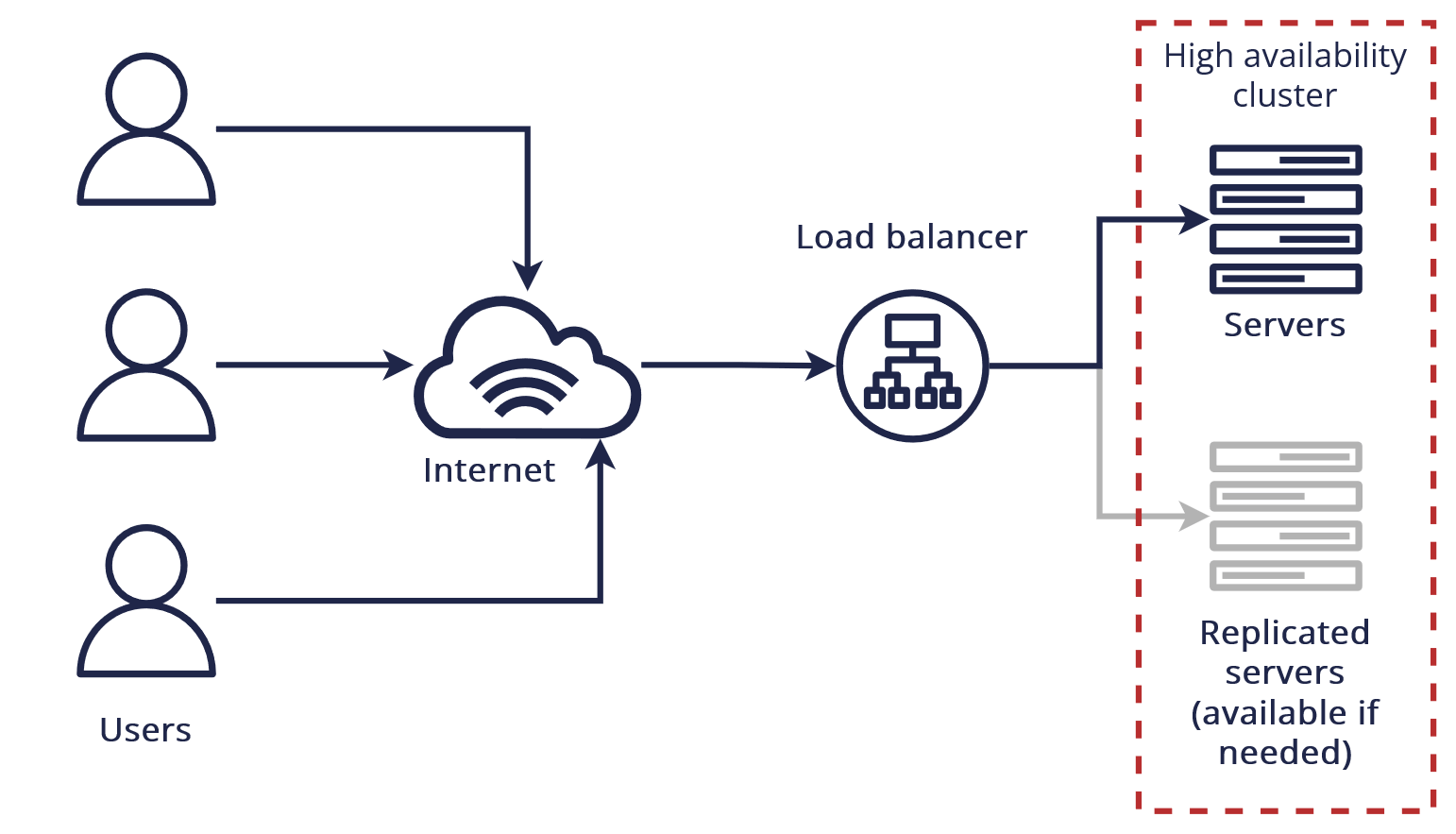
High availability for systems is represented through a sequence of “9s”. A 100% availability translates to 0 minutes of downtime in a year, which is possible in the public cloud, but it usually comes with a cost so high that businesses tend to avoid it.
- Three-nine availability, represented as 99.9%, allows 8 hours and 46 minutes of downtime per year.
- Four-nine availability, 99.99%, allows 52 minutes and 36 seconds of downtime per year.
- Five-nine availability, 99.999% which is the accepted standard for mission-critical operations, provides about 5 minutes and 15 seconds of downtime per year.
Here is a simple graph of how availability is calculated for complex infrastructures:

The following elements help you implement highly available systems:
- Reliability: in the sense that the system continues operating even when critical components fail.
- Resiliency: means that the system can simply handle failure without service disruption or data loss, and seamlessly recover from such failure.
- Redundancy: ensures that critical system components have another identical component with the same data, which can take over in case of failure.
- Monitoring: identifying problems in production systems that may disrupt or degrade service.
- Failover: the ability to switch from an active system component to a redundant component in case of failure, imminent failure, degraded performance or functionality.
- Failback: the ability to switch back from a redundant component to the primary active component when it has recovered from failure.
AWS high availability
The AWS (Amazon Web Services) Cloud is unique in building high availible business applications since AWS’ high availability delivers features that let you build these applications with little interaction and minimal upfront investment.
AWS recommends following these guidelines:
- Design the system to have no single point of failure. This can usually be achieved via load balancing, or by a pair of nodes in an active-standby configuration.
- Prepare operating procedures for manual or automatic mechanisms to respond to, mitigate, and recover from the failure.
AWS high availability with zones
AZs are isolated places with servers (data centers) located within regions in which AWS operates. At this moment there are 25+ regions and the minimum number of AZ in regions is two.
The use of multiple AZs enables customers to replicate workloads across the physical location.

Depending on the workload, it can be difficult to configure deployment across multiple AZs, but almost every AWS service has it covered and you just need to use the right settings. We’ll cover this more thoroughly in the next section of this blog post.
AWS Compute, Databases and Storage High Availability
Most applications will rely on these AWS services, which can be divided depending on their usage in multi-tier applications:
- Compute: Compute dimension contains AWS services like Amazon EC2 and AWS Lambda.
- SQL Databases: Amazon RDS and other managed SQL databases provide RDS high availability options.
- Storage Services: Such as S3, EFS, and EBS.
In the sections that follow, we’ll look more closely at each.
AWS computing high availability
EC2 high availability
Amazon Elastic Compute Cloud (Amazon EC2) compute resources are made highly available by using multiple instances at the same time to collectively process incoming requests.
This group of Amazon EC2 instances can be managed with Amazon EC2 Auto Scaling.
You achieve a reasonably good level of high availability by using the following services and features:
- Availability Zones (AZs) allow you to distribute EC2 instances across many locations. They provide a much greater level of protection against failure, as the data center itself is removed as a single point of failure.
- Elastic Load Balancing (ELB) allows you to launch several EC2 instances and spread traffic between them. As ELBs exist outside of any particular AZ, they are themselves insulated from AZs failure.
- Auto-scaling allows for the health of Amazon EC2 instances to be monitored and also self-healed by spinning up new compute instances if an existing one fails, with feature support to help cater for stateful applications.
- Elastic IP addresses, for example, can reroute a workload from one EC2 instance to another instantaneously.
Best practices for EC2 instance high availability
- It's recommended that you run EC2 instances in multiple AZs. If these zones become unavailable due to natural circumstances or power outage, Elastic Load Balancer can route traffic to operational AZ.
- And if you need more than one instance in every AZ, it's recommended you use Auto Scaling which automatically increases the number of instances to meet your high traffic demands and save you money by stopping the instances which are no longer needed.

AWS Lambda high availability
AWS Lambda has high availability built in and it runs your function in multiple AZs to ensure that it is available to process events in case of a zone failure.

AWS high availability for Amazon RDS
Amazon Relational Database Service (RDS) is similar in some ways to EC2 because RDS instances are EC2 instances managed by AWS. RDS's high availability is achievable by spreading multiple instances with the same data across AZs.
AWS supports two options of RDS for HA:
Amazon RDS Multi-AZ Deployments: In Multi-AZ deployments, Amazon RDS automatically generates a primary DB instance and synchronously replicates the data to a standby instance in a separate AZ.
This can be used for MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server.
In the event of an infrastructure (AZ) failure, Amazon RDS automatically switches to the backup database instance in the separate AZ.

- Amazon Aurora Multi-AZ achieves high availability by replicating data six times across three AZs. But this is only a storage layer.

You can also choose to run one or more replicas in an Amazon Aurora DB cluster. RDS automatically promotes an existing Aurora Replica to be the new primary replica and changes server endpoints in the event of a primary replica failure in a DB cluster, allowing your application to continue running without human intervention.

If a problem is detected and no replicas are provisioned, RDS will immediately spawn a new replacement DB instance for you, providing AWS RDS high availability for all your needs.
High Availability for AWS storage services
AWS offers storage for every use case and achieves high availability in a unique way.
Amazon Simple Storage Service (S3)
This service provides object storage for videos, pictures, documents, and more, offering secure, durable, and scalable object storage for a vast majority of projects in AWS.
S3 has high-availability built-in and offers 99.99% availability for object storage with 99.999999999% durability (based on storage type selected).
Depending on which storage tier you choose, data in an Amazon S3 storage bucket may be stored in just one AZ. Data will become unavailable if an S3 storage service disruption affects that AZ.
Amazon Elastic File Storage (EFS)
This option provides a managed file storage solution for Linux instances and offers an SLA of four-nine availability (99.99%). Amazon EFS can be used to provide redundancy across AZs, as well as providing the capability to mount the same file system concurrently from multiple Amazon EC2 instances.
Amazon Elastic Block Store (EBS)
This is a block storage service that is designed to work with Amazon EC2 instances and is highly scalable and high-performing.
Although Amazon EBS storage is internally replicated to several servers within an AZ, there is no redundancy outside of this zone. To achieve this, you would need to use Amazon EBS snapshots to create copies of the data in Amazon S3.
Amazon FSx
This is a high-performance file system. As a fully managed service, it handles hardware provisioning, patching, and backups Amazon FSx protects your data against failure by automatically replicating it inside or across AWS AZs.
Network high availability
One of the most important facets of highly available systems is the management of connectivity. In the event of a failure, clients need to be able to find any currently active nodes to re-establish communication and data operations.
Amazon Route 53 DNS
It provides highly available DNS services that can perform health checks on its targets and perform automatic failover for both active-active or active-passive configurations.
AWS NAT gateway high availability
NAT Gateway is a zone service. If you have resources communicating through it in multiple AZs, and if the NAT gateway’s AZ is down, resources in the other AZs lose Internet access too.
Depending on your business requirements, make sure to create NAT Gateways in at least two AZs.
Amazon API Gateway high availability
API Gateway is not built into one AZ, so it is highly available from the start.
Monitoring
Monitoring is paramount when it comes to high availability, and for this AWS provides Amazon CloudWatch, which can be used to monitor most services.
High availability vs. fault tolerance
The most basic difference between fault tolerance and high availability is this: A fault-tolerant environment has no service interruption but a significantly higher cost, while a highly available environment has a minimum service interruption but less cost.
Many businesses are willing to absorb a small amount of downtime with high availability rather than pay the much higher cost of providing fault tolerance.
It must be said that in the AWS Cloud the fault tolerance and high availability for some services can be so close together that you can say they are the same.
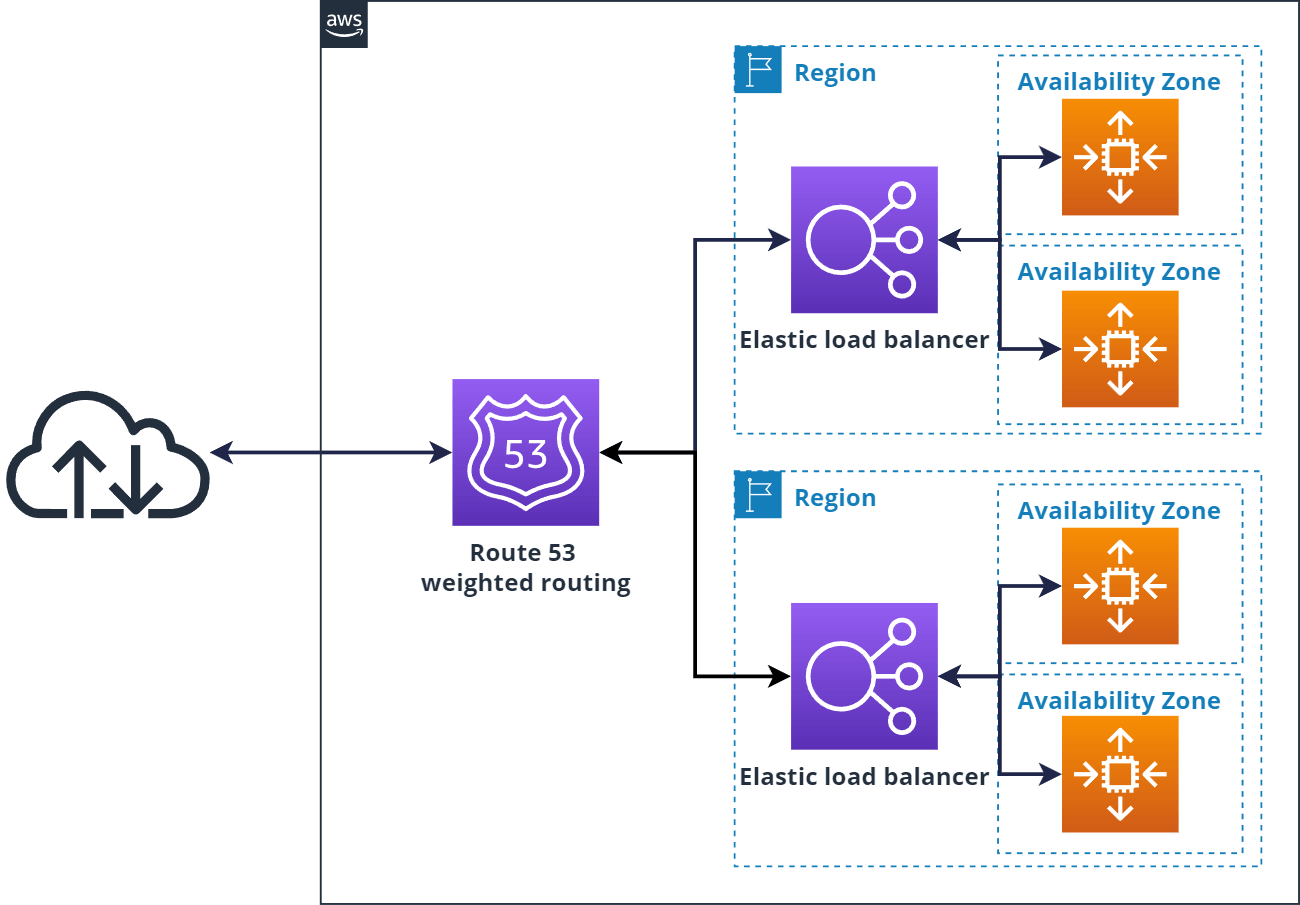
The typical example of AWS high availability vs fault tolerance is simple architecture with EC2 instances spread across AZs in the Auto Scaling group and Application load balancer (ALB). This architecture can be seen as High-Available.
If you take this architecture and copy it to another AWS region, it can be seen as fault-tolerant. You can also leverage Route 53 as DNS and route your users with weighted routing.
AWS high availability best practices
Regardless of the specific AWS tools and services in use, the following best practices can help you:
- Secure your credentials and environment: You can have the best services available at any time in the public cloud, and everything set up perfectly for high availability, but if there is a breach in your system and the intruder decides to stop your services, it can mean downtime. Secure your environment with AWS best practices in mind and MFA.
- Be mindful of the expenses: When creating infrastructure with high availability or redundancy, consider the cost of infrastructure. This should be compared to the benefits of the bill to determine if it is worth it. You can also use AWS cost optimization tools.
- Anticipate and plan for software failures: Creating effective incident response plans helps mitigate the risk of failures in the software. High availability doesn’t avert the possibility of software malfunctions.
- Data backups are essential for maintaining data integrity and ensuring high availability. Data loss is a significant risk no matter where data is stored. This is due to issues such as data deletion or the failure of backup servers or application instances. Even with high availability protections in place, it's important to perform regular backups.
FAQs
High availability means designing so that a component can fail without taking the app down – typically by spreading resources across multiple Availability Zones (Multi-AZ), removing single points of failure, and automating failover.
High availability keeps the system up during failures. Scalability adjusts capacity to handle changing load. On AWS, you usually combine both (e.g., ALB/NLB + Auto Scaling across Multi-AZ).
Core building blocks: Multi-AZ deployments, Elastic Load Balancing, Auto Scaling groups, managed Multi-AZ data stores (e.g., Amazon RDS/Aurora, DynamoDB), Amazon S3/EFS, Amazon Route 53 (health-check routing/failover), and CloudFront (edge delivery, multi-origin failover).
Yes. S3 stores data redundantly across multiple AZs in a Region and is designed for high availability. For Regional resilience use Cross-Region Replication and, if needed, multi-Region routing (e.g., via Route 53/CloudFront).
Yes – within a Region, Lambda runs across multiple AZs by default. For Regional outages, deploy to multiple Regions and route with Route 53 (active/active or failover).
AWS provides service-specific SLAs (they vary by service/Region). Your application’s uptime target (e.g., “four nines”) depends on your architecture – typically Multi-AZ and, for stricter targets, multi-Region with automated failover.
Conclusion
This blog introduces you to high-availability systems and the services AWS provides to implement them. AWS's high availability requires minimal manual intervention and low up-front financial investment, making AWS the best choice for building applications and infrastructure.

An AWS Solutions Architect with over 5 years of experience in designing, assessing, and optimizing AWS cloud architectures. At Stormit, he supports customers across the full cloud lifecycle — from pre-sales consulting and solution design to AWS funding programs such as AWS Activate, Proof of Concept (PoC), and the Migration Acceleration Program (MAP).

